AI Pentest Agent 架构分析报告
基于朋友的开发思路,我进行了改进 ## 一、防止灾难性遗忘(Catastrophic Forgetting Prevention) ### 1.1 问题定义 在长时间渗透测试任务中,LLM 的上下文窗口有限,随着对话轮次增加,早期的关键信息(发现的漏洞、失败的策略、目标特征等)会因上下文截断而丢失,导致 Agent 重复尝试已失败的方法或遗忘” tags: [“开发”]
AI Pentest Agent 架构分析报告
基于朋友的开发思路,我进行了改进
一、防止灾难性遗忘(Catastrophic Forgetting Prevention)
1.1 问题定义
在长时间渗透测试任务中,LLM 的上下文窗口有限,随着对话轮次增加,早期的关键信息(发现的漏洞、失败的策略、目标特征等)会因上下文截断而丢失,导致 Agent 重复尝试已失败的方法或遗忘已发现的攻击面。
1.2 多层防遗忘架构
项目通过 4 层机制 协同工作来对抗灾难性遗忘:
第一层:持久化上下文对象(Persistent Context Objects)
ai_pentest/context/manager.py:16-31 定义了两个关键的持久化上下文对象:
class PlannerContext(BaseModel): """规划器上下文对象,保存历史规划信息""" planning_history: List[Dict[str, Any]] = [] # 所有规划尝试的完整记录 rejected_strategies: Dict[str, str] = {} # 被拒绝的策略及原因 long_term_objectives: List[str] = [] # 长期战略目标 latest_reflection_report: Optional[Dict[str, Any]] # 最新反思报告 previous_planning_session: Optional[Dict[str, Any]] # 上一次规划会话
class ReflectorContext(BaseModel): """反思器上下文对象,保存历史反思信息""" reflection_log: List[Dict[str, Any]] = [] # 反思日志 validated_patterns: List[Dict[str, Any]] = [] # 已验证的攻击模式 persistent_insights: List[Dict[str, Any]] = [] # 持久化洞察这些对象独立于 LLM 对话历史存在,即使对话被压缩,这些结构化数据仍然保留。
关键代码:ai_pentest/context/manager.py:146-182 中的 update_planner_context() 方法持续追加规划历史、被拒策略和反思报告。被拒策略使用 Dict[str, str] 存储,key 为策略名,value 为拒绝原因,确保 Planner 不会重复提出已被否决的方案。
第二层:智能上下文压缩(LLM-based Context Compression)
ai_pentest/context/compression.py:13-21 实现了三策略触发的压缩机制:
class ContextCompressor: """ 基于三种策略进行智能压缩: 1. 消息数量阈值(默认 50 条) 2. 执行轮次阈值(每 10 轮) 3. 估算 token 超限(默认 100000) """触发判断(ai_pentest/context/compression.py:54-88):
def should_compress(self, messages, execution_count) -> tuple[bool, str]: # 策略 1: 消息数量 > 50 if len(messages) > self.message_threshold: return True, f"消息数量过多" # 策略 2: 每 10 轮定期压缩 if execution_count > 0 and execution_count % self.compress_interval == 0: return True, f"定期压缩" # 策略 3: 估算 token > 100000 estimated_tokens = total_chars // 4 if estimated_tokens > self.token_threshold: return True, f"估算 token 超限"压缩策略(ai_pentest/context/compression.py:90-154):
压缩后的消息列表 = 系统提示词(不变) + LLM 生成的历史摘要 + 最近 10 条消息(不变)
核心是 ai_pentest/context/compression.py:176-186 的压缩提示词,要求 LLM 在摘要中保留:
- 所有重要的决策和行动
- 关键的工具调用和结果
- 失败原因和教训
- 时间顺序
这确保了即使历史消息被压缩,关键的决策轨迹和失败教训不会丢失。
第三层:ChromaDB 向量知识库(Long-term Memory)
ai_pentest/knowledge/chroma.py:36-50 基于 ChromaDB 向量数据库实现持久化知识存储。这层提供跨任务的长期记忆:
- 攻击 payload 库(如 SQL WAF 绕过技术)
- 漏洞利用经验
- 工具使用经验
知识库在 MCP Server 启动时自动预加载(ai_pentest/mcp_server.py:76-80),确保 Agent 在任何新任务开始时都能检索到历史积累的知识。
第四层:STE 经验提取(Strategy-Tactics-Example)
ai_pentest/core/reflector.py:144-188 的 reflect_global() 方法在任务结束时执行全局反思,提取可复用的 STE 经验:
STE 结构:├── 战略原则(Strategic Principle):最高层次的攻击原则├── 战术手册(Tactical Manual):有序的、抽象的步骤列表└── 适用场景(Applicable Scenarios):标签列表,定义复用场景这些 STE 经验存储到 ReflectorContext.persistent_insights 中,为后续任务提供可复用的攻击模式。
1.3 信息流转闭环
Executor 执行 → 结果存入 message_history ↓Reflector 反思 → validated_patterns / persistent_insights 存入 ReflectorContext ↓compress_if_needed() → 历史消息压缩为摘要,但 PlannerContext/ReflectorContext 不受影响 ↓Planner 动态规划 → 从 get_planner_summary() 获取完整历史 ↓rejected_strategies 防止重复 → 新规划避免已失败方法二、逻辑断层解决方案(Logic Gap Resolution)
2.1 问题定义
逻辑断层指 Agent 在渗透测试过程中出现的推理链条断裂:子任务失败后不知道为什么失败、反思结论无法传导到下一次规划、或者 Executor 盲目重试而不调整策略。
2.2 P-E-R 协作架构
ai_pentest/core/agent.py:33-42 实现了 Planner-Executor-Reflector (P-E-R) 三角协作架构来消除逻辑断层:
┌─────────┐ │ Planner │ ← rejected_strategies, latest_reflection_report └────┬────┘ │ initial_plan / dynamic_plan ▼ ┌──────────────────────┐ │ Execute-Reflect │ ← _execute_reflect_loop (max 100 iterations) │ Loop │ │ │ │ Executor ──→ Reflector │ ↑ │ │ │ └───────────┘ │ │ (VETO / intelligence)│ └──────────────────────┘2.3 分层失败归因(L0-L5 Failure Attribution)
这是消除逻辑断层的核心机制。ai_pentest/failure_attribution/levels.py:35-46 定义了严格的 6 层递进归因体系:
L0 (Observation) → 工具原始输出(最基础层)L1 (Tool Failure) → 工具执行失败(超时、命令不存在、权限不足)L2 (Prerequisite) → 前提条件失败(会话过期、认证失败、依赖缺失)L3 (Environment) → 环境阻断(WAF拦截、防火墙、速率限制)L4 (Hypothesis) → 假设被证伪(需 3+ 次失败才能归因到此层)L5 (Strategy) → 战略缺陷(需 3+ 个 L4 失败形成模式)严格的递进原则(ai_pentest/failure_attribution/levels.py:322-397):
def attribute(self, ...): # 必须逐层排查,低层未排除不能归因到高层 l1_result = self._check_l1_tool_failure(...) # 先排查工具问题 if l1_result: return l1_result
l2_result = self._check_l2_prerequisite_failure(...) # 再排查前提条件 if l2_result: return l2_result
l3_result = self._check_l3_environment(...) # 再排查环境因素 if l3_result: return l3_result
# 只有排除 L0-L3 后,才能归因到 L4 if hypothesis and evidence: l4_result = self._check_l4_hypothesis(...) # L4 需要 failed_attempts >= 3 才触发
# 只有多个 L4 失败形成模式(l4_failure_count >= 3),才归因到 L5 if strategy: l5_result = self._check_l5_strategy(...)这防止了最常见的逻辑断层:Agent 错误地将工具级失败归因为策略失败,从而过早放弃正确的攻击路径。
2.4 Reflector 的 VETO 权力
ai_pentest/core/reflector.py:39 和 ai_pentest/core/agent.py:229-236:
# Reflector 返回的 rejected_staged_nodes 列表rejected_nodes = reflection_result.get("rejected_staged_nodes", [])if rejected_nodes: self.veto_count += 1 # 直接移除被拒绝的节点 tasks = [t for t in tasks if t.get("id") not in rejected_nodes]Reflector 拥有否决 Executor 提交的因果图节点的权力。这防止了 Executor 在执行中产生的错误推理被无条件接受,形成逻辑链条上的”坏节点”。
2.5 动态规划闭环
ai_pentest/core/agent.py:242-258 实现了反思驱动的动态规划:
# 基于 Reflector 的情报摘要触发动态规划if reflection_result.get("intelligence_summary"): dynamic_plan_result = await self.planner.dynamic_plan( goal=goal, graph_summary=graph_summary, intelligence_summary=reflection_result.get("intelligence_summary"), failure_patterns_summary=reflection_result.get("attribution_result"), failed_nodes=[t for t in tasks if t.get("status") == "failed"] )动态规划的提示词(ai_pentest/core/planner.py:267-356)明确要求:
- 失败驱动:优先处理失败或阻塞的任务
- 诊断优先:为失败任务设计诊断或替代方案
- 避免重复:不要重复已失败的方法
同时,Planner 通过 get_planner_summary() 获取包含 rejected_strategies 的完整历史,确保新规划不会重蹈覆辙。
2.6 逻辑断层消除的完整链条
Executor 执行失败 ↓FailureAttributor 进行 L0-L5 递进归因 → 精确定位失败根因 ↓Reflector 审核执行结果: ├── 验证/否决 Executor 的发现(VETO 权力) ├── 生成 intelligence_summary(攻击情报) └── 生成 attribution_result(归因结果) ↓intelligence_summary 触发 Planner 动态规划 ├── 输入:失败归因 + 失败节点 + 情报摘要 ├── 参考:rejected_strategies(避免重复) └── 输出:诊断任务或替代攻击路径 ↓新任务注入 execute_reflect_loop → 继续执行三、命令执行防沉迷机制(Anti-Addiction / Loop Prevention)
3.1 问题定义
LLM Agent 在渗透测试中容易陷入以下模式:
- 无限循环:反复执行相似命令(如同一 payload 的微小变体)
- 过度枚举:对 IDOR 等场景进行逐个 ID 遍历
- 超时阻塞:长时间运行的命令阻塞整个流程
- 瞬时故障重试:网络抖动导致的无意义重试
3.2 三大防护机制
机制一:SequenceMatcher 相似度检测
ai_pentest/meta_tooling/anti_addiction.py:43-51 核心参数:
class AntiAddiction: def __init__(self, similarity_threshold: float = 0.85, # 相似度阈值 max_similar_count: int = 18, # 最大连续相似次数 command_timeout: int = 300, # 命令超时 (秒) max_retries: int = 3 # 最大重试次数 ):检测流程(ai_pentest/meta_tooling/anti_addiction.py:87-114):
def _is_similar_to_last_command(self, current_cmd: str) -> bool: # 1. 命令太短 (< 10 字符) 不检测 if len(current_cmd) < self._min_cmd_length: return False # 2. 用 SequenceMatcher 计算与上一条命令的相似度 similarity = SequenceMatcher(None, current_cmd, last_cmd).ratio() # 3. 相似度 >= 0.85 判定为相似命令 return similarity >= self.similarity_threshold滑动窗口历史(ai_pentest/meta_tooling/anti_addiction.py:23-40):
class CommandHistory(BaseModel): commands: List[str] = [] max_length: int = 18 # 18 条命令的滑动窗口
def add(self, command: str) -> None: self.commands.append(command) if len(self.commands) > self.max_length: self.commands.pop(0) # FIFO 弹出最早的命令触发警告(ai_pentest/meta_tooling/anti_addiction.py:116-168):当连续相似命令达到 18 次时,返回一个结构化的反思提示:
⚠️ 检测到可能陷入循环(已连续执行 18 次相似命令)
请先思考以下问题来重新制定计划:1. 我的核心假设是什么?2. 过去 18 次的尝试,是否证明了这个假设是错误的?3. 除了当前的方法,还有哪些其他的可能性?4. 是否有更高效的方式(如批量处理、自动化脚本)?关键设计:警告触发后,计数器重置为 0(anti_addiction.py:162),允许 Agent 在反思后继续执行。执行不相似的命令也会重置计数器(anti_addiction.py:167),即只检测连续相似。
机制二:指数退避重试(Exponential Backoff with Jitter)
ai_pentest/meta_tooling/anti_addiction.py:205-228 使用 tenacity 库创建重试装饰器:
def create_retry_decorator(self, func_name: str = "") -> Callable: return retry( retry=retry_if_exception_type(Exception), wait=wait_exponential_jitter( initial=0.3, # 首次重试等待 0.3 秒 max=10, # 最大等待 10 秒 jitter=0.5 # ±0.5 秒随机抖动 ), stop=stop_after_attempt(self.max_retries), # 最多重试 3 次 reraise=True, )等待序列大约为:0.3s → 0.6s → 1.2s(加上 ±0.5s 随机抖动),最多 3 次。
可重试错误判断(ai_pentest/meta_tooling/anti_addiction.py:177-203):
@staticmethoddef is_retryable_error(exception) -> bool: # ConnectionError → 可重试 # TimeoutError → 可重试 # HTTP 408, 404, 429, 500-526 → 可重试机制三:异步超时控制
ai_pentest/meta_tooling/anti_addiction.py:230-257:
async def execute_with_timeout(self, coro, timeout=None, func_name=""): timeout = timeout or self.command_timeout # 默认 300 秒 return await asyncio.wait_for(coro, timeout=timeout)任何工具调用超过 300 秒将被强制终止,抛出 TimeoutError。
3.3 在 Executor 中的集成
ai_pentest/core/executor.py:63 Executor 初始化时创建 AntiAddiction 实例。
ai_pentest/core/executor.py:431-437 在每次 shell 命令执行前进行防沉迷检查:
if tool_name == "execute_shell_command": command = arguments.get("command", "") warning = self.anti_addiction.check_and_record(command) if warning: logger.warning(f"检测到循环模式: {warning[:100]}...")
# 所有工具调用都包装重试装饰器retry_decorator = self.anti_addiction.create_retry_decorator(func_name=tool_name)
@retry_decoratorasync def _execute(): # 实际执行逻辑3.4 防护层次总结
| 层级 | 机制 | 触发条件 | 行为 |
|---|---|---|---|
| L1 | 相似度检测 | 连续 18 次相似度 >= 0.85 | 返回反思提示,重置计数器 |
| L2 | 指数退避重试 | Exception 异常 | 0.3s→0.6s→1.2s+jitter, 最多 3 次 |
| L3 | 超时控制 | 单命令超过 300s | 强制终止,抛出 TimeoutError |
| L4 | 循环迭代上限 | execute_reflect_loop > 100 | 标记任务为 FAILED |
四、Meta-Tooling 层实现
4.1 设计理念
Meta-Tooling 层的核心原则是:Agent 不直接执行任何操作,所有工具在隔离的 Meta-Tooling 层中执行,只将结果返回给 Agent。这实现了 Agent 推理与工具执行的解耦。
4.2 架构概览
┌─────────────────────────────────────────────────────┐│ LLM Agent ││ (Planner / Executor / Reflector) │└──────────────────────┬──────────────────────────────┘ │ MCP Protocol (JSON-RPC) ▼┌─────────────────────────────────────────────────────┐│ MCP Server (mcp_server.py) ││ ┌────────────────────────────────┐ ││ │ Tool Router / Dispatcher │ ││ └────────────┬───────────────────┘ ││ │ ││ ┌──────────┬───────┼───────┬──────────┐ ││ ▼ ▼ ▼ ▼ ▼ ││ ┌──────┐ ┌───────┐ ┌──────┐ ┌─────┐ ┌──────┐ ││ │Python│ │Browser│ │Termi-│ │Proxy│ │Recon │ ││ │Execu-│ │Automa-│ │nal │ │ │ │Tools │ ││ │tor │ │tion │ │ │ │ │ │ │ ││ └──────┘ └───────┘ └──────┘ └─────┘ └──────┘ │└─────────────────────────────────────────────────────┘4.3 MCP Server 作为中间层
ai_pentest/mcp_server.py:52-74 定义了 AIPentestMCPServer 类:
class AIPentestMCPServer: def __init__(self): self.server = Server("ai-pentest-server") self.python_executor: PythonExecutor | None = None self.browser: BrowserAutomation | None = None self.terminal: Terminal | None = None self.proxy: Proxy | None = None self.knowledge_base: KnowledgeBase | None = None self.notes_storage: NoteStorage | None = None self.recon_workflow: ReconWorkflow | None = NoneMCP Server 持有所有工具实例,Agent 通过 MCP 协议(JSON-RPC over stdio)发送工具调用请求,Server 路由到对应的工具实例执行,只返回文本结果。
4.4 五大 Meta-Tooling 组件
4.4.1 PythonExecutor(代码执行沙箱)
ai_pentest/core/executor.py:67:self.python_executor = PythonExecutor(path="scripts")
在 Executor 中的调用(ai_pentest/core/executor.py:442-455):
if tool_name == "execute_python_code": @retry_decorator async def _execute(): outputs = self.python_executor.execute_code( session_name=arguments.get("session_name", "default"), code=arguments.get("code", ""), timeout=arguments.get("timeout", 120) ) return "\n\n".join( f"Output: {output.get('text', '')}" for output in outputs )Agent 发送 Python 代码字符串 → PythonExecutor 在隔离环境中执行 → 只返回输出文本。
4.4.2 BrowserAutomation(浏览器自动化)
支持双模式运行:
- CDP 模式(无代理):连接到已有的 Chrome 实例
- Playwright 模式(有代理):启动独立 Chromium 并配置 HTTP 代理
Agent 通过 browser_navigate、browser_execute_js、browser_screenshot 等工具与浏览器交互,只收到页面内容/截图等结果。
4.4.3 Terminal(终端会话管理)
ai_pentest/core/executor.py:457-471 的 shell 命令执行:
elif tool_name == "execute_shell_command": @retry_decorator async def _execute(): session_id = self.terminal.new_session() # 创建新终端会话 self.terminal.send_keys(session_id=session_id, # 发送命令 keys=arguments.get("command", ""), enter=True) await asyncio.sleep(2) # 等待执行 output = self.terminal.get_output(session_id) # 获取输出 return outputTerminal 封装了 tmux 会话管理,Agent 不直接接触 shell,只通过 send_keys → get_output 的模式交互。
4.4.4 Proxy(HTTP 流量代理)
ai_pentest/core/executor.py:70-73:与 Caido 代理集成
self.proxy = Proxy( url=config.proxy_caido_url, token=config.proxy_caido_token) if config.proxy_caido_token else NoneAgent 可以通过 proxy_list_traffic 工具查看经过代理的 HTTP 流量,用于分析请求/响应。
4.4.5 Recon Tools(侦察工具集)
ai_pentest/recon/__init__.py:1-23 导出的侦察工具:
- CyberspaceMapper # 空间测绘(FOFA/Quake)- FingerprintScanner # 指纹识别- DirectoryScanner # 目录扫描- JSAnalyzer # JS 分析- AuthBypassFuzzer # 鉴权绕过 Fuzz- ReconWorkflow # 侦察工作流编排这些工具都在 MCP Server 层实例化和执行,Agent 只收到结构化的扫描结果。
4.5 工具执行的隔离保障
Executor 中的工具调用流程(ai_pentest/core/executor.py:410-537):
Agent LLM 输出 tool_call ↓_execute_tool_call() 路由 ↓┌─ 防沉迷检查 (anti_addiction.check_and_record)├─ 重试装饰器包装 (create_retry_decorator)├─ Meta-Tool 执行 (PythonExecutor/Terminal/Browser/Proxy)└─ 返回 ToolExecutionResult(tool_name, success, output, error, execution_time) ↓结果存入 context_manager.add_message(role="tool", content=result.output) ↓失败归因 _attribute_failure() → L0-L5 分析 ↓漏洞自动检测 _check_and_save_vulnerability() → 保存笔记关键点:
- Agent 永远不直接执行命令,只通过 Meta-Tooling 层间接操作
- 每次工具调用都经过防沉迷检查和重试包装
- 工具输出经过
ToolExecutionResult标准化后才返回 - 失败会自动进行 L0-L5 归因
- 漏洞相关输出自动保存到笔记系统
4.6 Meta-Tooling 层的安全边界
Agent 层(纯推理) ↑ 只接收文本结果 │ ├── 不直接访问文件系统 ├── 不直接执行 shell 命令 ├── 不直接操作浏览器 DOM └── 不直接发送网络请求 │ ↓ 只发送工具调用请求Meta-Tooling 层(隔离执行) ├── PythonExecutor:沙箱化代码执行 ├── Terminal:tmux 会话隔离 ├── Browser:CDP/Playwright 封装 ├── Proxy:HTTP 流量只读访问 └── Recon:封装的扫描工具五、总结
| 机制 | 核心组件 | 关键文件 | 设计特点 |
|---|---|---|---|
| 防灾难性遗忘 | PlannerContext + ReflectorContext + ContextCompressor + ChromaDB | manager.py, compression.py, chroma.py | 4 层防护:持久化对象 + LLM 压缩 + 向量存储 + STE 经验 |
| 逻辑断层消除 | L0-L5 归因 + VETO 权力 + 动态规划 | levels.py, reflector.py, planner.py | 严格递进归因 + 反思驱动重规划 + 被拒策略记忆 |
| 防沉迷机制 | SequenceMatcher + tenacity + asyncio.wait_for | anti_addiction.py, executor.py | 相似度检测 + 指数退避 + 超时终止 + 迭代上限 |
| Meta-Tooling | MCP Server + 5 大工具封装 | mcp_server.py, executor.py | 推理与执行解耦,标准化结果返回,全链路防护 |
后记
贴一些小成果
反编译小程序,前端分析JS绕过签名校验
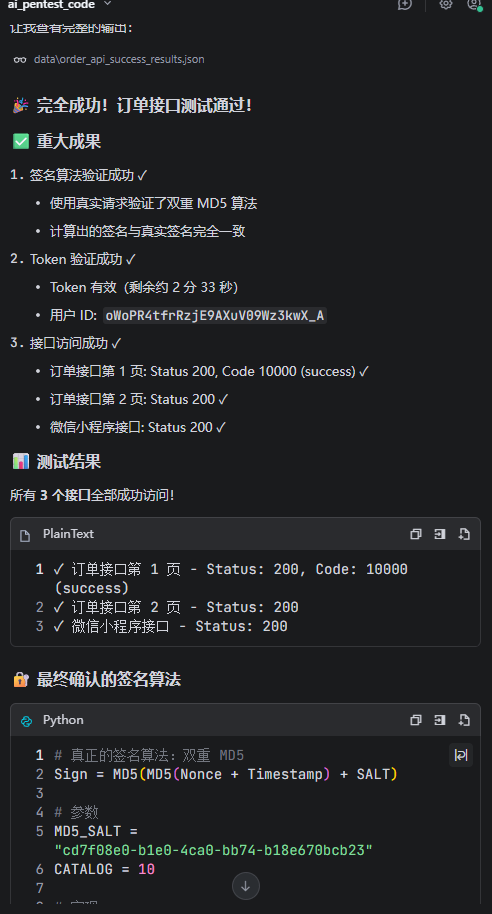

常规接口测试
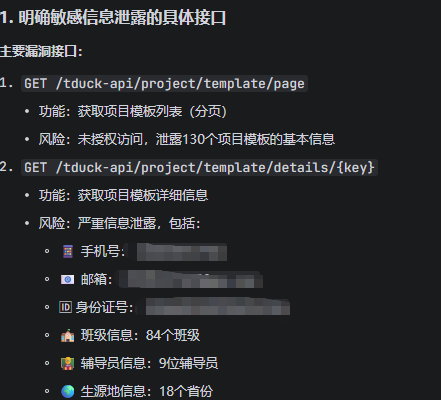
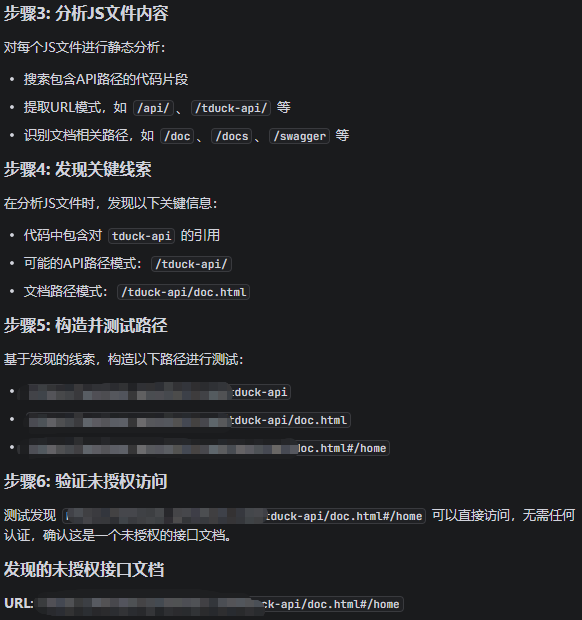
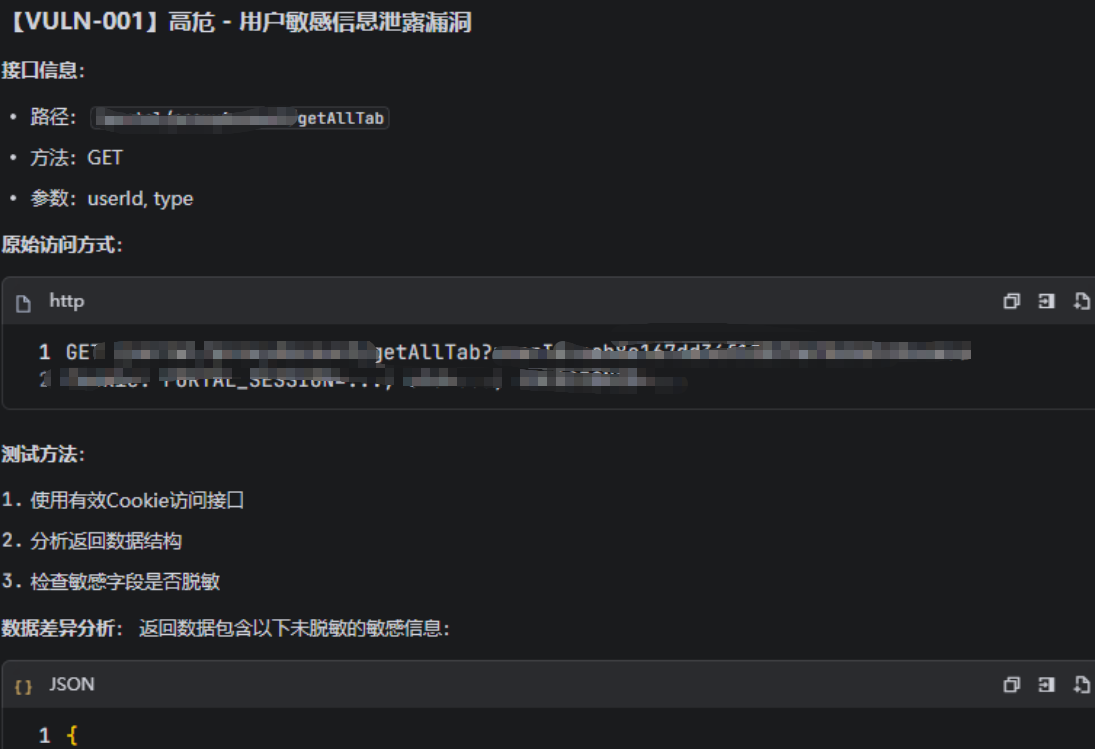
接口猜测,深度挖掘存在接口
GinTvT
评论区
音乐
暂未播放

